
In this post, we will see how HashMap works internally in java. This post has been written with reference to Java 8. We will cover the below points in this post.
Understanding what happens when we create an object of HashMap, Map<String, String> mapObject = new HashMap<>();
Understanding what happens when we add the first key-value pair.
Understanding what happens if we have a duplicate key.
Understanding hash collision.
Let’s see what happens when we create a HashMap Object and insert the first element as below.
package javabasic;
import java.util.*;
public class HashMapExample {
public static void main(String[] args) {
HashMap<String, String> mapObj = new HashMap<>();
}
}
When we create a HashMap object the default load factor of HashMap is initialized with 0.75.
Let’s see what happens when we add the first element as a key-value pair.
package javabasic;
import java.util.*;
public class HashMapExample {
public static void main(String[] args) {
HashMap<String, String> mapObj = new HashMap<>();
mapObj.put("ram", "156");
}
}
When we add the first key-value pair using put() method below points need to keep in mind.
- Hash code will be calculated for the key using the hash() method.
- The default initial capacity of HashMap will be calculated i.e 16.
- The initial threshold will be calculated using the default initial capacity and load factor ( i.e 16 * 0.75). Don’t forget the load factor is already initialized while creating the object of HashMap using the default constructor.
- A table will be created with an initial capacity of 16. The table has 16 rows, and each row of the table represents a bucket.
Node<K,V>[] table = (Node<K,V>[])new Node[16];
- Since we have a table with size 16, when we will try to add the first element it should be stored at some index. For now, suppose our first element is stored at the 15th index.
- The index will be calculated as follows.
index = (n-1) & hashcode. Here n = initial capacity i.e 16. In our case since the key is ram, the hashcode of ram is 112671 using hash() method. If we do System.out.println((16-1) & 112671), the output will be 15 and yes at 15th index first pair will get stored. We will see later how the index will be calculated in detail.
- Till now, We have the table with an initial capacity 16, the default load factor is 0.75 and the initial threshold will be 12(16 * 0.75) and also index has been decided where our first element going to sit.
- Each bucket is internally itself arrays of LinkedList and can contain more than one Nodes.

Till here we have added the first element as a key and value pair in HashMap using put() method. Before going ahead let’s see how put() method has been implemented. In put() method further putVal() method is getting called as below. Core logic has been defined inside putVal() method.
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
Let’s see what logic has been defined into putVal() method. Whatever we have discussed earlier once again we are going to look, how internally it’s working.
V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;// line no - 5
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//some more logic
}
In the above code snippet line number 5 i.e resize() method is responsible to create a table and initialize it with initial capacity i.e 16. Also, the threshold value will be calculated i.e 12.
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
//some more logic
newCap = DEFAULT_INITIAL_CAPACITY;// 16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//12
threshold = newThr;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//table with size newCap i.e 16
table = newTab;
//some more logic
return newTab;
}
Just wait. Till now we have seen how initial capacity, the threshold is decided and also how the table is created with size 16. Did you remember in the default HashMap’s constructor we are only initializing default load factor? Table creation and some other stuff happen when put() method get called. No doubt further inside put() method putVal() is getting called and then resize() method. Hope till this point we are good. Let’s come back to putVal() method.
V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // line no - 6
tab[i] = newNode(hash, key, value, null);
else {
//some more logic
}
Now have a look at highlighted line i.e 6. What’s going on. This is the code(i = (n – 1) & hash]) which decides index, where our first element i.e (“ram”, 156) is going to stay. Let’s do one thing, just write a simple program and run separately in eclipse and observe the output.
package javabasic;
import java.util.*;
public class HashMapExample {
public static void main(String[] args) {
int n = 16;
int hash = 112671; // hashcode of "ram" after hash(key) method
System.out.println("index of our key ram is = " +((n-1) & hash));
}
}
Output is – index of our key ram is = 15
This is a brief how the index is getting calculated. Let’s have a look into this code snippet of putVal() method.
tab[i] = newNode(hash, key, value, null); Here we are calling newNode() method which is creating a new Node.
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
This is how our first node is creating and it will get stored into 15th index(which we can see in the above diagram). In the above code snippet, we have return new Node<>(hash, key, value, next). Here we are creating an object of Node class. Node is an inner class which has been defined as below.
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
Let’s add another key-value (“mohan”, 168) and see what happens.
package javabasic;
import java.util.*;
public class HashMapExample {
public static void main(String[] args) {
HashMap<String, String> mapObj = new HashMap<>();
mapObj.put("ram", "158");
mapObj.put("mohan", "156");
}
}
First hashcode will be calculated for key “mohan” using the hash() method.
The index will be calculated the same way(n-1 & hashcode of mohan).
The new node will get created and it will stay at some index(as of now 7th index).

Same way if we add some more element with different key and value pair, the index will be decided and a new node will be created and it will be stored at some index. Just for better understanding let’s see how does the table look after adding two key-value pairs.

Now, what will happen if we have a duplicate key? For example, suppose we are going to insert (“mohan”, 159).
import java.util.HashMap;
import java.util.Map;
public class Test1 {
public static void main(String[] args) {
Map<String,String> mapObj = new HashMap<>();
mapObj.put("ram","158");
mapObj.put("mohan","156");
mapObj.put("mohan","159");
}
}
For the above code, Since we have duplicate key hashcode will be the same and don’t forget index will also be the same as we have already seen index = (n-1) & hashcode. In this case index will 7 again. Once again have a look into putVal() method.
V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//some more logic
if ((p = tab[i = (n - 1) & hash]) == null){//line no - 5
tab[i] = newNode(hash, key, value, null);
}else {
Node<K,V> e; K k;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))//line no 9
e = p;//line no -10
//some more logic
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;//line no -15
afterNodeAccess(e);
return oldValue;
}
}
}
Let’s have a look at line number 5. Since we have already element at index 7, Node<K, V> p has already been initialized, and if condition will not satisfied and else part will execute(new node will not be created). In the else part, we have a new node Node<K, V> e which initialized with p(line 10) since if condition(line 9) is true (as we have the same key and yes equals() method will be used to compare the key). At line 15 old value will replace with the new value. This is all about what happens when we have a duplicate key.
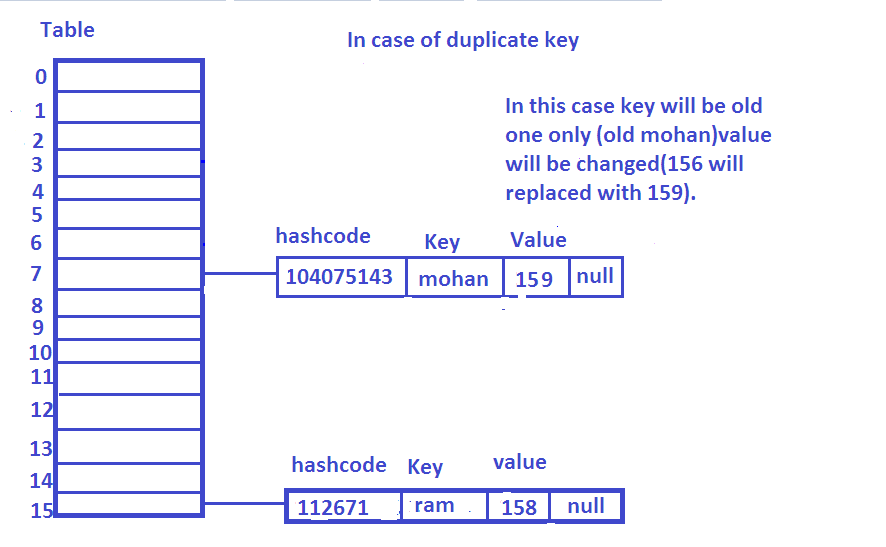
[stextbox id=’info’]In the above case (i.e inserting duplicate key) we have seen new node will not be created and old value will be replaced with the new value. What about the key? Do we have a new key or old one only? Key is still old mohan only value is getting changed.[/stextbox]
Let’s see what is a hash collision and what happens in case of a hash collision. We are going to insert two key-value pairs, where two different keys will have the same hashcode.
package javabasic;
import java.util.*;
public class HashMapExample {
public static void main(String[] args) {
HashMap<String, String> mapObj = new HashMap<>();
mapObj.put("ram","158");
mapObj.put("mohan","156");
mapObj.put("mohan","159");
//String "0-42L" and "0-43-" has same hash value even both are two different String
mapObj.put("0-42L","156");//line 15
mapObj.put("0-43-","159");//line 16
System.out.println(mapObj);
}
}
Out put is – {mohan=159, 0-42L=156, 0-43-=159, ram=158}
Let’s see what going on. We have already discussed till line 12. When line 15(mapObj.put(“0-42L”,”156″)) will execute, the index will be calculated and a new node will be created and (“0-42L”, “156”) will stay at this index i.e 8. When line 16(mapObj.put(“0-43-“,”159”)) will execute since we have the same hashcode index will also be the same and also since we have a different key, it will create a new node which will link to the previous node which is staying at index 8. How?
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//some more logic
}
Here p = new Node(hashcode, “0-42L”, “156”, null); // Here next node will link with null someting like below.

In the above diagram at the 8th index, we have two nodes. Same way if we have some key which has hashcode 45720776 is going to stay 8th index but that must be different(it should not duplicate). This is all about what happens in case of a hash collision.
Just for better understanding –


In the two above diagram, we have two nodes in the 8th position.
Summary : –
- HashMap uses the hash() method to calculate the hashcode of the key.
- While creating the object of HashMap using the default constructor load factor will initialize with 0.75.
- When we store the first key-value pair using put() method, the table will be created of type Node class(inner class) and since this is an array its size will be decided i.e 16. The initial threshold will also decide i.e 12.
Node<K,V> [] table;
- The index will get calculated and New Node will be created and key-value will be stored to this index.
- If the key will be duplicate, it will not create a new node, the only old value will be replaced with the new value. The equals() method will use here.
- In case of a hash collision, the new node will be created and it will store at the same index.
Important note – In older versions of Java (prior to Java 8), the HashMap implementation did use a linked list to handle collisions. When multiple keys hashed to the same bucket, they were stored in a singly linked list at that bucket. This linked list structure allowed for efficient handling of collisions.
However, starting from Java 8, the HashMap implementation was improved to handle collisions differently for better performance. It uses a combination of linked lists and red-black trees to store key-value pairs in the same bucket. When a bucket contains too many elements (threshold varies based on load factor and bucket size), it transitions from a linked list to a red-black tree. This change was introduced to ensure that the worst-case time complexity for operations remains O(log n) instead of O(n) in the case of very large hash chains.
So, while HashMap still employs linked lists to some extent, it is more sophisticated in its handling of collisions in Java 8 and later versions to maintain efficient performance.
That’s all about How HashMap works internally in Java.
You may like –
- How get method of ArrayList work internally in java.
- How HashSet works internally in java.
- How ArrayList works internally in Java.
- User defined class as key in HashMap in Java.
- Sort HashMap by value in java.
- Sort HashMap by key in java.
- Performance in case of HashMap and Hashtable.
- Different ways to iterate TreeMap in Java.
- Constructors and methods of TreeMap in Java.
- TreeMap in java.
- Constructors and methods of LinkedHashMap in Java.
- Different ways to iterate LinkedHashMap in Java.
- LinkedHashMap in Java.
- Constructors and methods of Hashtable in Java.
See HashMap docs here.
Summary – We have seen here how HashMap works internally in Java.
 Example in Java")

 Example in Java")